Our series on operationalizing AI document workflows continues. This time: why LLMs fall short when the math gets complex — and how code execution closes the gap.

Regulatory and clinical documents don't just contain prose — they're built on data. Efficacy endpoints, adverse event rates, analytical test results, patient demographics, stability data. Numbers run through every section, and in many cases, they're the most scrutinized part of the submission.
The teams we work with are increasingly relying on AI to handle not just the writing, but the calculations themselves — computing values, running summaries, transforming data into structured report sections. For basic arithmetic, LLMs are accurate. But when the math gets complex — nonlinear calculations, statistical analyses, percentiles, or processing thousands of data points — LLMs fall short, and the results aren't reliable enough for a regulatory submission.
And the danger is that the LLM won't tell you it got it wrong. Ask it to compute a percentile across a biostatistics dataset, and it will return a confident, well-formatted result that looks exactly like a correct one. Teams may not realize they've crossed the line from where the model is reliable to where it isn't — and a wrong number in a submission can set a drug or device launch back by months, potentially costing millions and delaying patient access.
Calculated, Not Generated
This is why Everest doesn't rely on the LLM alone for quantitative work. With Code Interpreter, the system leverages native code execution capabilities across leading AI models to write and run Python against the actual source data. For sections that involve things like statistical summaries, derived metrics, or data transformations — especially across large datasets — the numbers are calculated directly from the data.
A natural place to start is with validation. In the example below, Code Interpreter is performing intelligent QC on a statistical analysis — comparing reported values against what the underlying data actually implies. The system independently calculates the expected p-value from the reported effect size and standard errors, flags the inconsistency, and presents both scenarios for the author to evaluate.
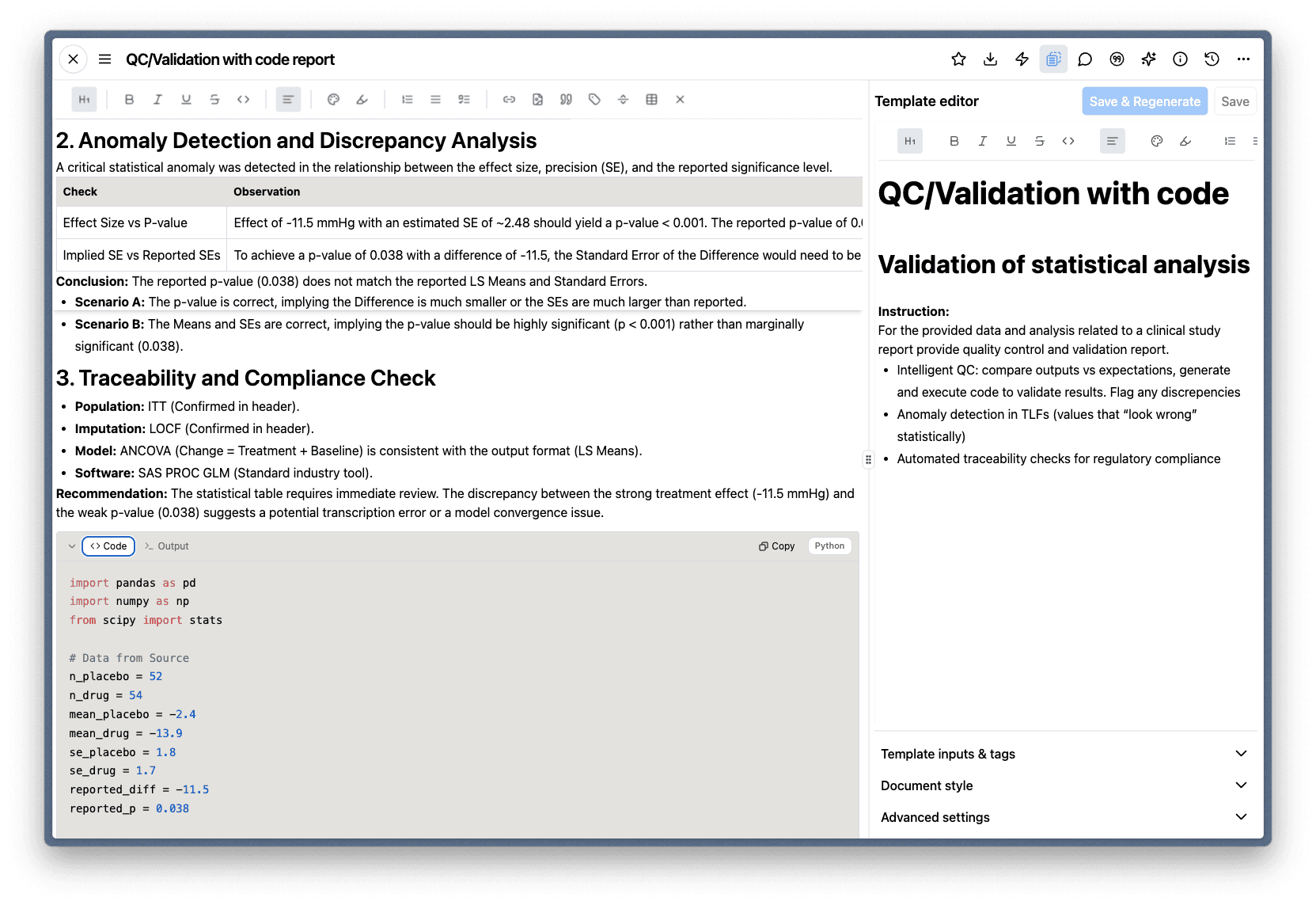
Code Interpreter writes and executes Python to validate reported statistical results against the source data.
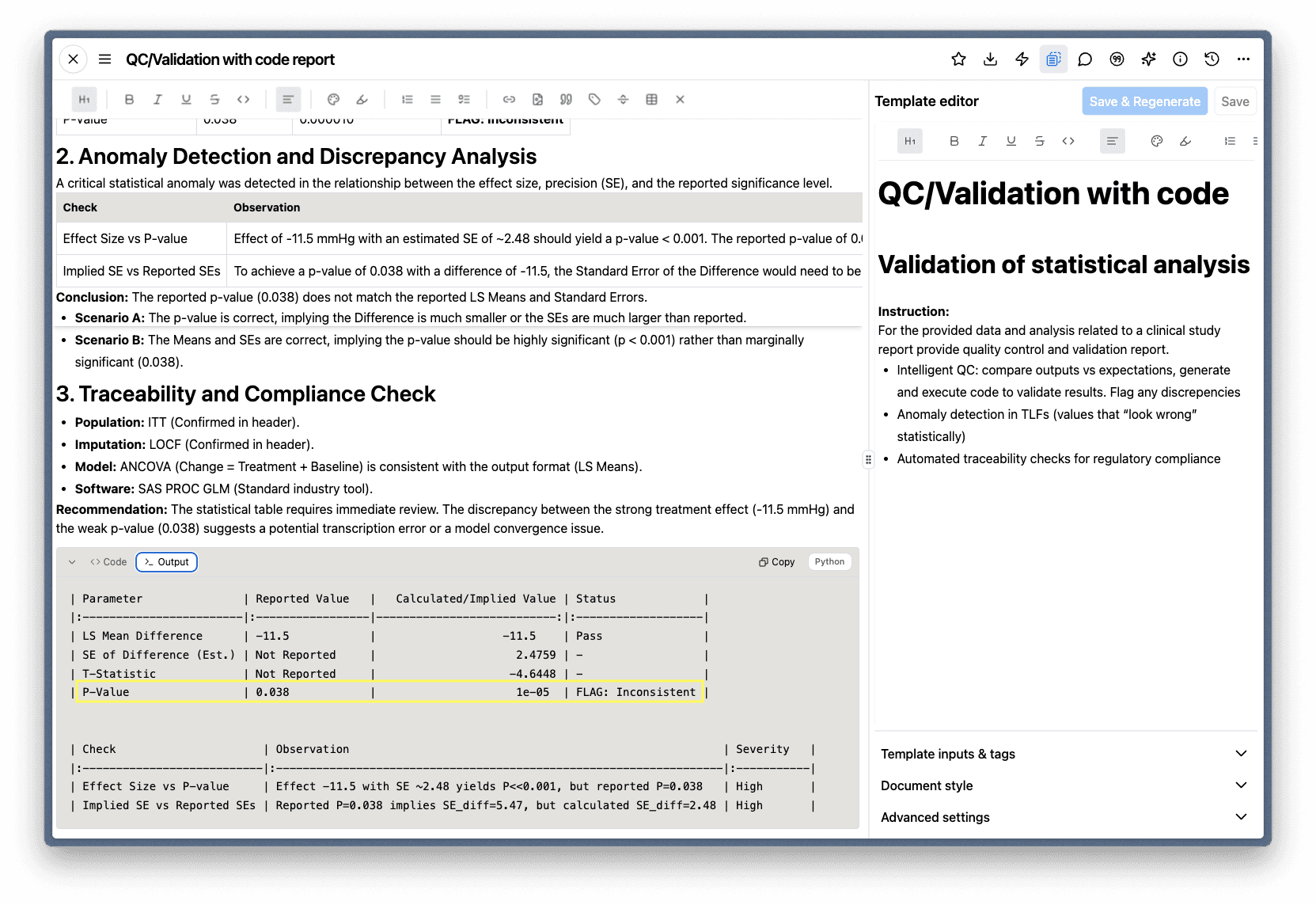
The output compares reported values to calculated values and flags discrepancies — here, a p-value that doesn't match the reported effect size and standard errors.
Notice that the QC instructions — what to check, what to flag — are defined directly in the template. This means the same validation runs automatically every time the report is generated, not just when someone remembers to do it.
Authors don't have to take the results on faith. Each section includes a collapsible view showing the code that ran and the execution result, both independently copyable. The reasoning is fully transparent — authors can verify not just what the system produced, but how it got there.
The setting is scoped per template, so teams can enable Code Interpreter for the sections that need it while using standard generation for narrative sections. It's precision where precision matters.
AI-generated documents shouldn't ask you to trust the numbers. They should show you the math. And if a human made an error along the way? The code will catch that too.
Next in the Series
Even the best AI workflows don't exist in a vacuum. In "Working With Your Data — Seamlessly," we look at how teams connect Everest to the systems where their documents already live.